Basic machinery = Jupyter + Python
jupyter github python

Welcome to Notebooks
When you start an analysis, you don’t really know how it will go. Maybe data is bad and there is no real reason to analyze anything at all. Maybe data data outliers that need to be dealt with. Maybe data is too sparse and cannot be analyzed using standard approaches. Whatever is the case there are multiple steps that depend on each other. Because real analyses contain many such steps it is easy to end up with tangled mess of little scripts that cannot be comprehended even by their own author. As Steven Skiena points out in his book “The data science design manual”:
The primary deliverable for a data science project should not be a program. It should not be a data set. It should not be the results of running the program on your data. It should not just be a written report. The deliverable result of every data science project should be a computable notebook tying together the code, data, computational results, and written analysis of what you have learned in the process.
Get your first notebook
We will start by using Colaboratory to start a Jupyter notebook that is stored on GitHub.
Go to http://collab.research.google.com:
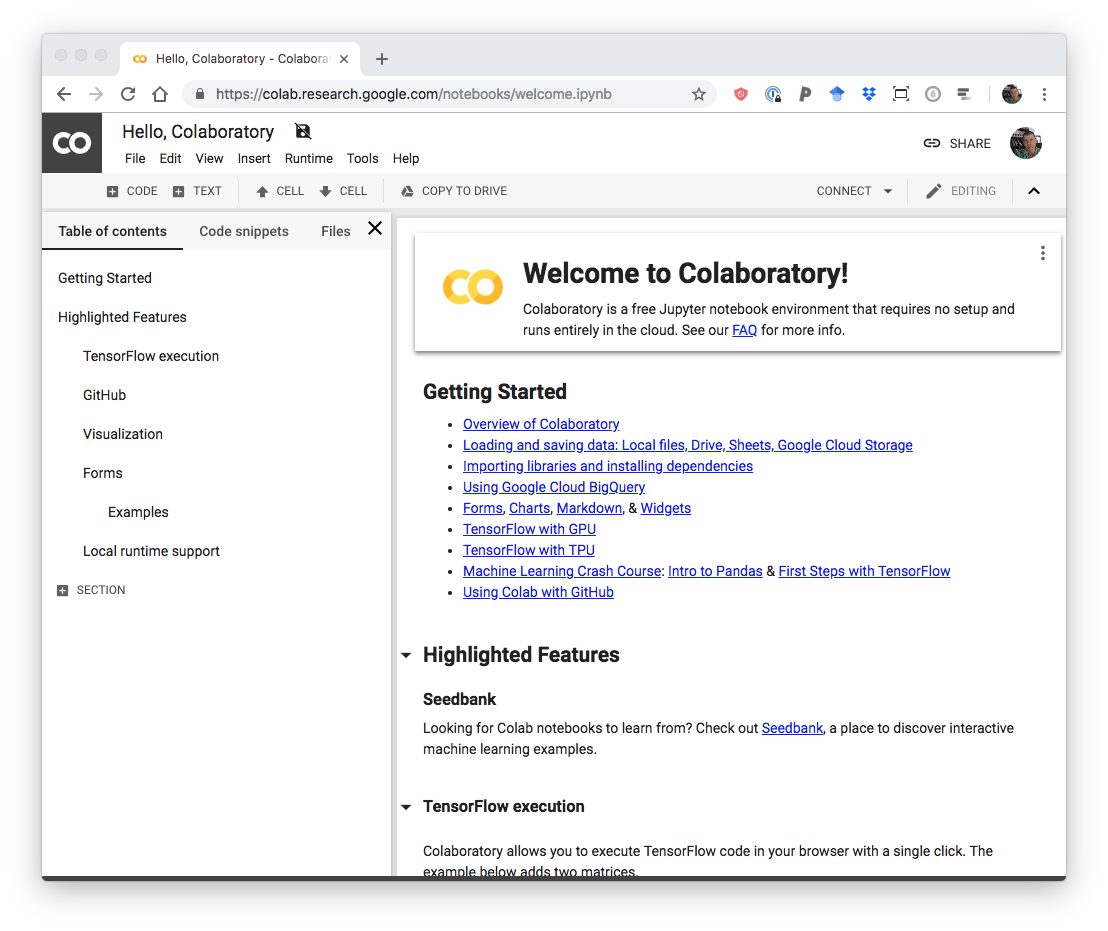
Default Colaboratory interface.
Select “Upload notebook” (you will be prompted for Google sign-in):
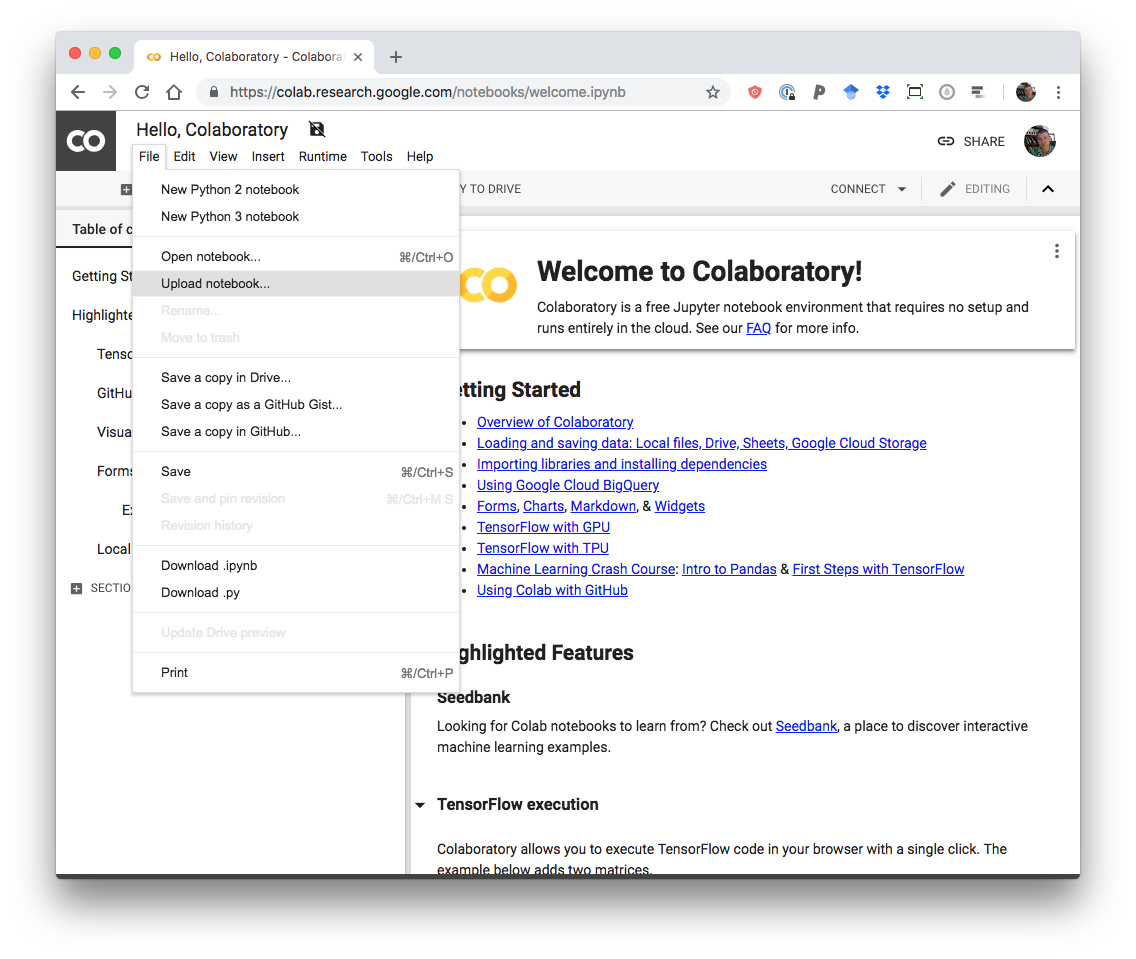
Select “Upload notebook”.
Use https://github.com/nekrut/BMMB554 as the source URL and select 2020/jptr.ipynb:
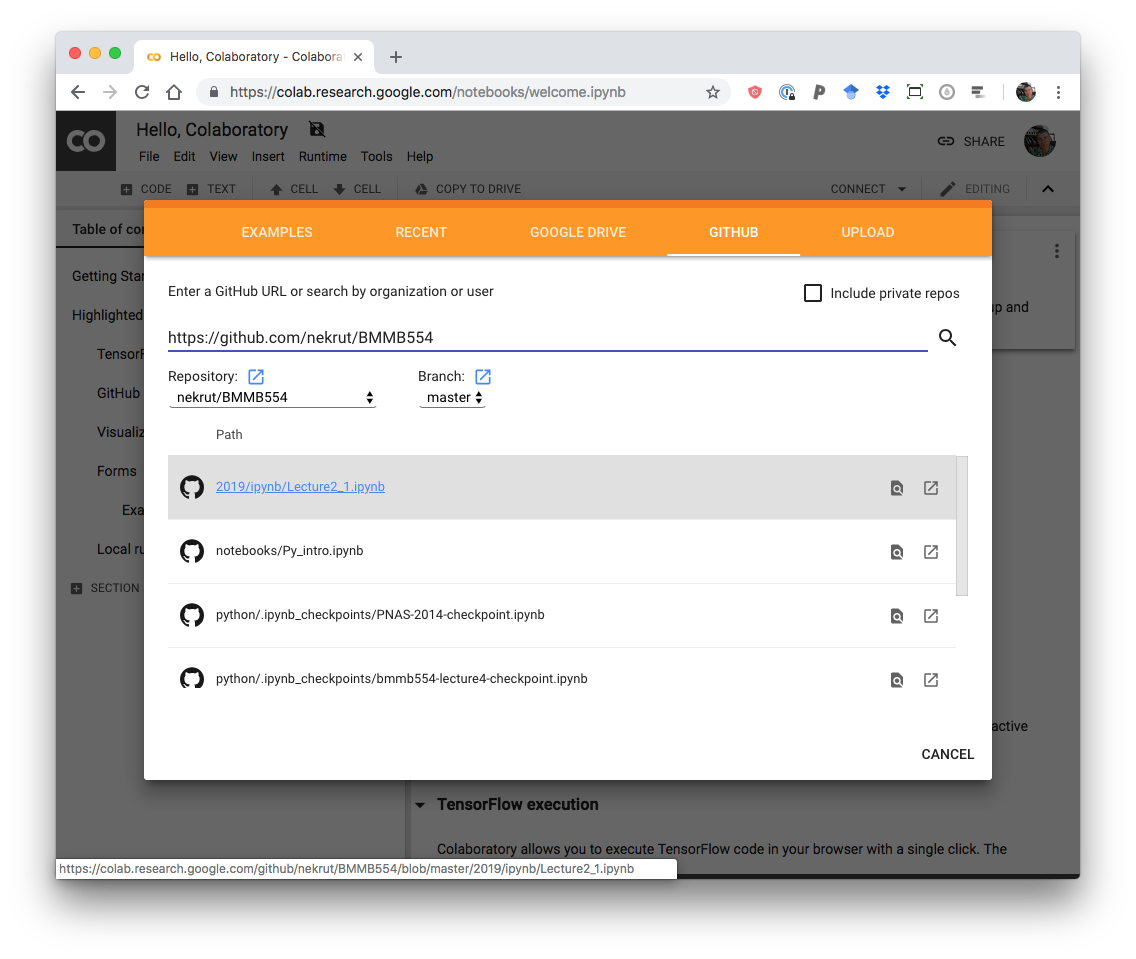
Select 2020/jptr.ipynb.
You will see something like this:
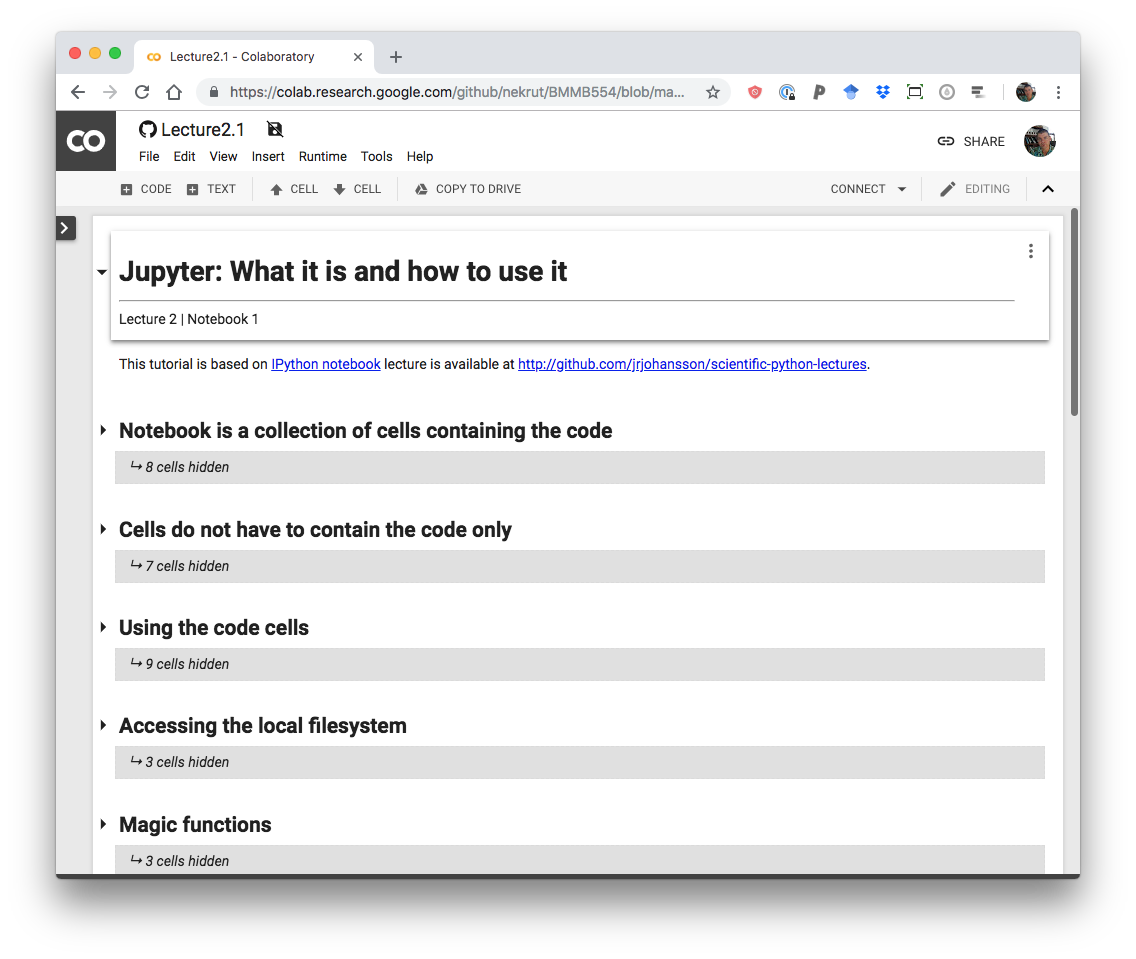
A freshly rendered notebook.
Make a copy of this notebook
The notebook you just uploaded is immutable - you cannot make any changes to it. To claim it as your own use “Save a copy in Drive…” option:
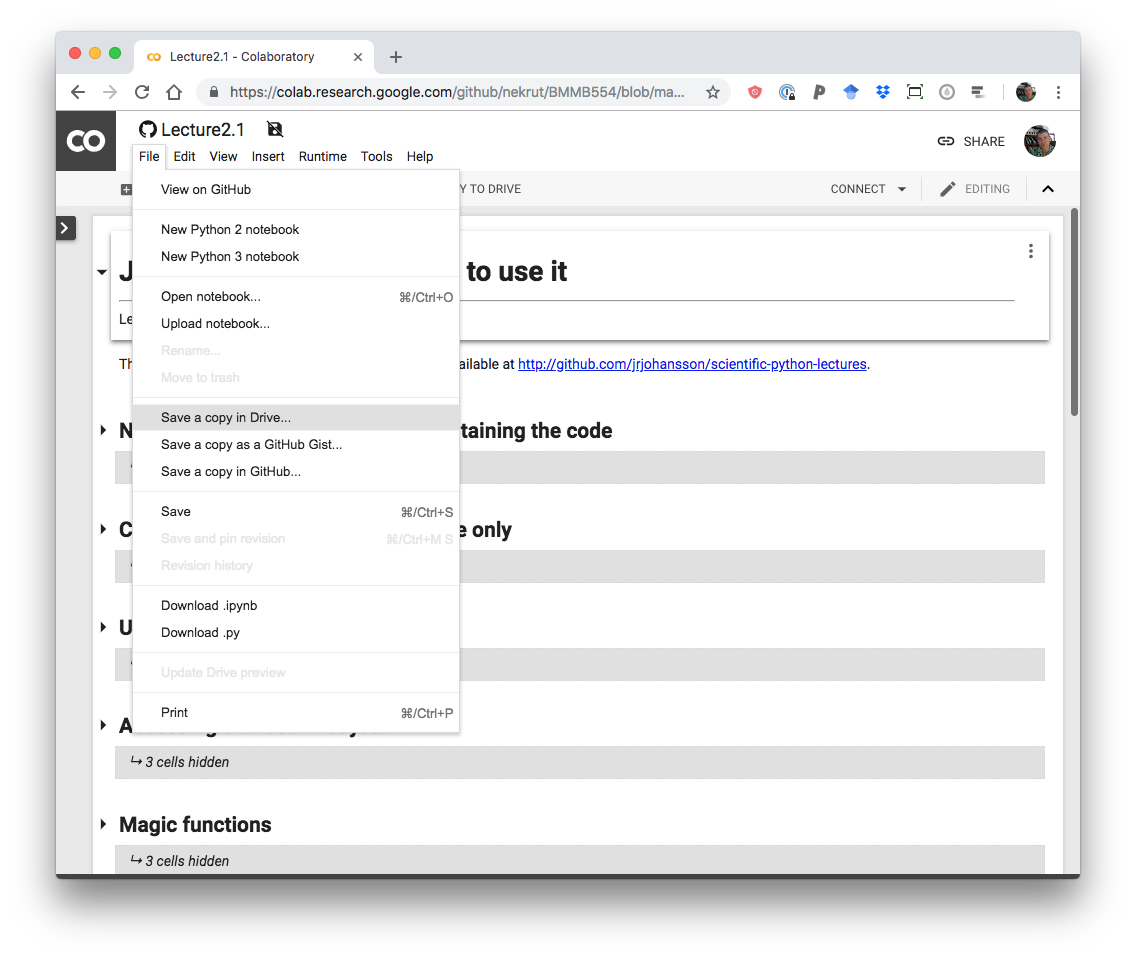
Make a copy!
Jupyter ecosystem is HUGE
We will use Jupyter for virtually everything in this course. It is worth noting that anything is indeed possible in Jupyter as highlighted by this very large list of known tutorials.